pas2js with SQLite WebAssembly, demo 2
Second demo up!
There are two programs in this demo: a driver program loaded by the demo page, that then loads the worker program. The worker program runs SQLite operations in a separate thread, away from the web browser's main UI thread, keeping the browser responsive.
Tags: Pascal, SQLite, WebAssemblypas2js with SQLite WebAssembly, demo 1
Happy Chinese New Year! Today is the first day of the year of the Fire Horse.
I've put up a demo of pas2js invoking WebAssembly SQLite.
In this demo, the pas2js program's SQLite database operations run in the web browser's main UI thread. Reload the web page if the output doesn't appear automatically; this may have to do with caching by your web browser, caching cleverness by HTMX, reverse proxy caching on my site, or other web weirdness.
The next demo's program will do its database work in a separate worker thread.
Tags: Pascal, SQLite, WebAssemblyHybrid native/web Android app with dwindows and Free Pascal
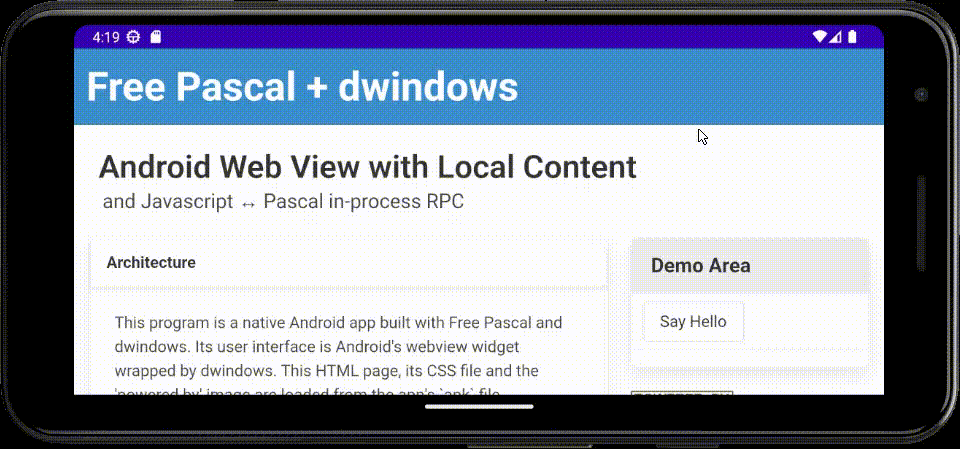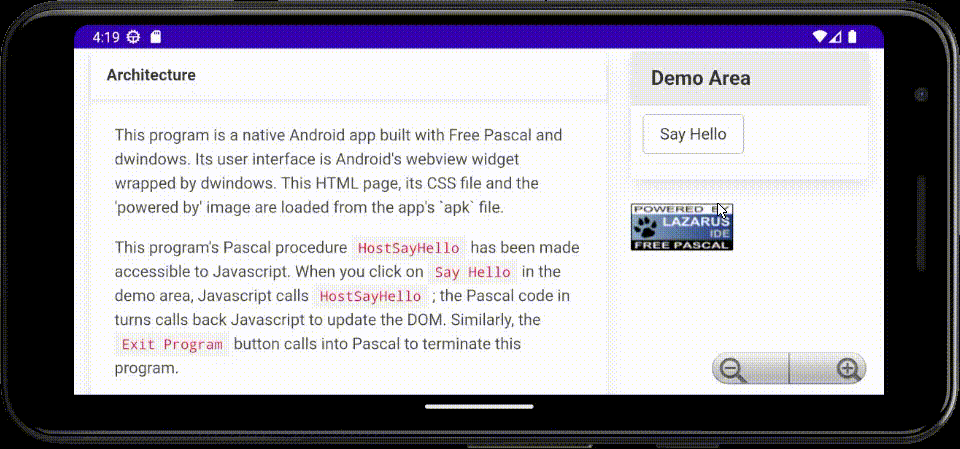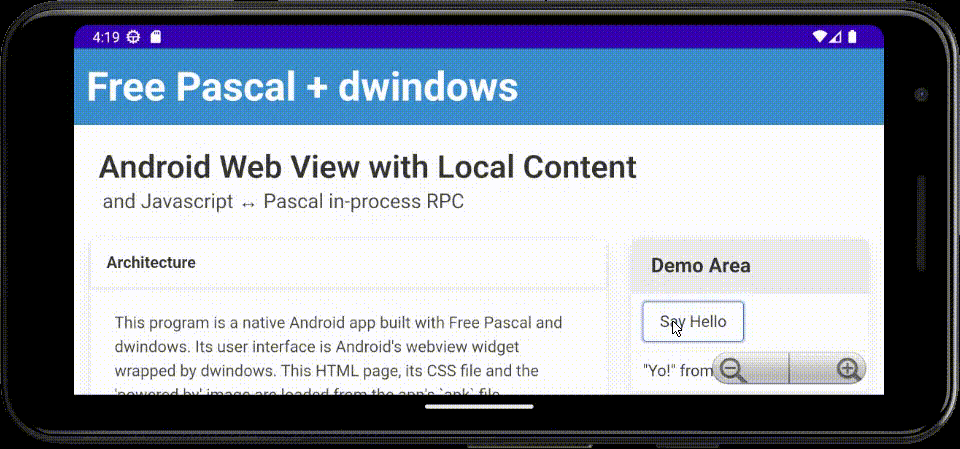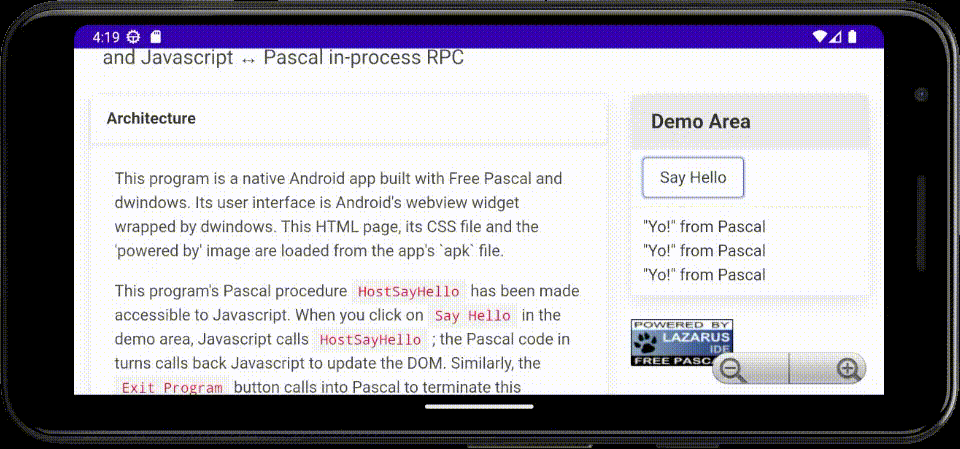
Coming back to dwindows after a (long) break, I've now implemented an Android hybrid native/web demo/exercise app in Free Pascal, using a webview widget for the user interface, with bi-directional Javascript ↔ Pascal in-process RPC.
The main body of the code loads in-app static content packaged into the APK file, then binds the
names HostSayHello and HostExit for callback to Pascal from Javascript. Said Pascal code can
in turn invoke Javascript to manipulate the DOM.
webwidget := dw_html_new(1001); // 1001 is an identifier
if webwidget <> nil then
begin
dw_box_pack_start(mainwindow, webwidget, 0, 0, DW_TRUE, DW_TRUE, 0);
dw_html_url(webwidget, 'file:///android_asset/index.html');
dw_html_javascript_add(webwidget, 'HostSayHello');
dw_html_javascript_add(webwidget, 'HostExit');
dw_signal_connect(webwidget, DW_SIGNAL_HTML_MESSAGE, @html_message_callback, nil);
end;
Here's an animated GIF of the app running in the Android emulator on my laptop:
fpwebview updates
I've published latest updates to fpwebview:
- library files for x86_64 for Linux, macOS and Windows
- library files for i386 for Windows
- library file for aarch64 for macOS
- built from latest webview (commit dated Feb 2024)
- built from WebView2 1.0.2365.46 (published Feb 2024)
- demos updated to match changes in webview
- LCL embedding demo tested with Lazarus 3.2
